
Databricks Launches Storage-Optimized Vector Search for Billion-Scale Datasets
Key Facts
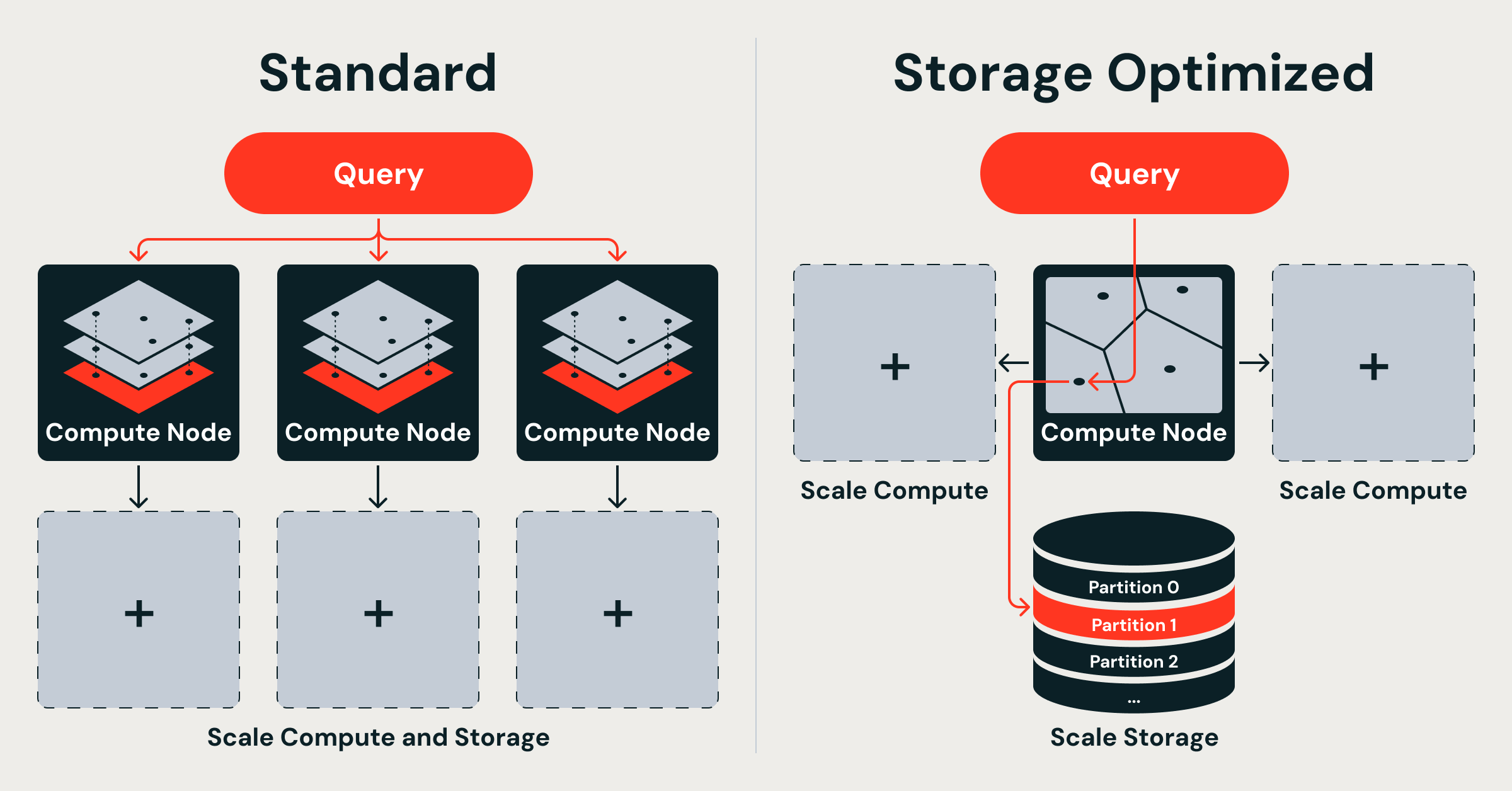
- What: Databricks introduced Storage Optimized endpoints for Vector Search, a decoupled architecture that separates storage from compute to serve billions of vectors at significantly lower cost.
- How: Vector indexes are stored in cloud object storage and loaded into memory only for serving; ingestion uses isolated ephemeral serverless Spark clusters; queries are handled by a custom Rust engine with dual thread pools.
- Performance: Billion-vector indexes can be built in under 8 hours with 20x faster indexing and up to 7x lower serving costs compared to tightly coupled designs.
- Trade-off: Storage Optimized endpoints deliver query latencies in the hundreds of milliseconds, versus tens of milliseconds for the existing Standard (in-memory) endpoints.
- Use Cases: Designed for cost- and scale-sensitive workloads such as retrieval-augmented generation (RAG), recommendation systems, and entity resolution on massive datasets.
Databricks has redesigned its vector search offering from first principles to address the scaling challenges of billion-vector datasets. The new Storage Optimized endpoints decouple storage, compute, and ingestion, allowing organizations to serve massive vector indexes from cloud object storage at a fraction of the cost of traditional in-memory vector databases. This launch directly tackles limitations the company encountered with its original vector search product, which relied on memory-resident indexes that become prohibitively expensive at scale.
The announcement, detailed in a technical blog post titled "Decoupled by Design: Billion-Scale Vector Search," explains how traditional vector database architectures begin to break as datasets grow from millions to billions of vectors. Memory costs explode, ingestion interferes with serving, and scaling requires replicating both data and compute resources. By separating these layers, Databricks claims its new approach delivers dramatically better economics while maintaining production-grade performance for workloads where sub-100ms latency is not required.
The Problem with Traditional Vector Databases
Many production vector databases, including Databricks' own Standard Vector Search endpoints, follow a shared-nothing architecture derived from distributed keyword search systems. In this design, each node owns a random shard of the dataset and maintains an independent in-memory Hierarchical Navigable Small World (HNSW) graph over full-precision vectors.
While HNSW provides excellent search quality and low latency, the requirement that the entire graph reside in memory creates severe scaling issues. At 768 dimensions with 32-bit floats, 100 million vectors consume roughly 286 GiB of RAM for the vectors alone, before accounting for index overhead. Scaling to a billion vectors would require multiple terabytes of expensive RAM.
The tight coupling of index, raw data, and serving compute on the same nodes creates multiple operational problems. Scaling storage requires scaling compute proportionally. Ingestion and index maintenance compete directly with query serving for the same resources, causing latency spikes during write-heavy periods and stalled ingestion during query spikes. Every upsert, delete, or compaction triggers sub-index rebuilds that consume CPU cycles otherwise available for serving.
Random sharding further compounds inefficiency. Because vectors are distributed without regard to semantic similarity, every query must fan out to all shards, increasing CPU usage, network overhead, and tail latency as the number of shards grows.
Decoupled Architecture and Engineering Decisions
Databricks' Storage Optimized Vector Search is built on a fundamental premise: all data lives in cloud object storage, and query nodes remain stateless. This separation creates a three-layer architecture that breaks the traditional coupling along two key boundaries — storage from compute, and ingestion from serving.
The design rests on three core engineering decisions:
1. Separate storage from compute. Vector indexes reside in cloud object storage and are loaded into memory only when needed for serving. Query nodes do not own persistent data, allowing storage to scale independently and at much lower cost than RAM.
2. Build distributed indexing algorithms on Spark. Rather than relying on single-machine indexing libraries, Databricks developed native Spark-based distributed clustering, vector compression, and partition-aligned data layout algorithms. These jobs scale linearly with cluster size and run on ephemeral serverless Spark clusters that are completely isolated from the query serving path.
3. Serve queries from a Rust engine with a dual-runtime architecture. A purpose-built query engine written in Rust uses separate thread pools for asynchronous I/O operations and CPU-bound vector computations. This prevents either workload from starving the other, maintaining stable performance even under mixed loads.
The result of these decisions is a system capable of building billion-vector indexes in under 8 hours, achieving 20x faster indexing, and delivering up to 7x lower serving costs compared to memory-resident designs.
Two Deployment Options for Different Workloads
Databricks Vector Search now offers two distinct deployment options to address varying requirements:
-
Standard endpoints maintain full-precision vectors entirely in memory to achieve tens-of-milliseconds query latency. These are suitable for latency-sensitive applications where response time is critical.
-
Storage Optimized endpoints prioritize cost and scale over ultra-low latency. By leveraging object storage and loading indexes on demand, they serve billions of vectors at significantly reduced cost, with query latencies typically in the hundreds of milliseconds. This represents a deliberate engineering trade-off for workloads where cost efficiency and massive scale matter more than sub-100ms responses.
Both options are built on the same underlying Mosaic AI Vector Search platform, allowing customers to choose the right balance of performance and economics for their specific use cases.
Competitive Context in Billion-Scale Vector Search
Databricks enters a rapidly evolving market for large-scale vector search infrastructure. Several major players have recently announced advances targeting billion-scale datasets.
AWS recently announced general availability of GPU-accelerated vector (k-NN) indexing on Amazon OpenSearch Service, claiming the ability to build billion-scale vector databases in under an hour with up to 10x faster indexing at a quarter of the previous cost. OpenSearch's GPU-accelerated approach also emphasizes a decoupled design to enable future hardware and algorithmic improvements.
Academic and open-source efforts have produced additional innovations. Researchers presented GustANN, a GPU-centric, CPU-assisted approximate nearest neighbor search (ANNS) system designed for high-throughput, cost-effective billion-scale vector search on SSDs. Other projects, such as VectorChord 1.1, have demonstrated scaling vector search to 1 billion vectors directly within PostgreSQL.
ScyllaDB has also positioned itself strongly in the space, claiming the fastest vector search performance in publicly available benchmarks and targeting real-time AI workloads at massive scale.
Databricks' approach differentiates itself through deep integration with the Spark ecosystem, native use of serverless Spark clusters for indexing, and a Rust-based query engine optimized for the decoupled storage model. The company emphasizes that its solution was born from real operational pain points encountered while running its previous vector search offering at scale.
Impact for Developers and Enterprises
For organizations building AI applications on Databricks, the new Storage Optimized endpoints significantly improve the economics of vector search at scale. Applications involving retrieval-augmented generation, semantic search across massive document corpora, recommendation systems with billions of embeddings, and large-scale entity resolution can now operate more cost-effectively.
The separation of ingestion from serving is particularly valuable for workloads with continuous data updates. Organizations can refresh indexes without degrading query performance, enabling more frequent updates to knowledge bases and embedding collections.
Developers benefit from the same APIs and integration points as the Standard endpoints, allowing them to experiment with the cost-optimized tier without rewriting application code. The ability to choose between Standard and Storage Optimized endpoints within the same platform provides flexibility as workloads evolve.
The lower cost profile may also enable new use cases that were previously economically unfeasible. Companies with extremely large embedding collections — such as those processing entire internet-scale datasets or maintaining comprehensive product catalogs — can now consider vector search as a core infrastructure component rather than a luxury feature.
What's Next
Databricks has positioned the Storage Optimized Vector Search as a foundational improvement that addresses the core scaling limitations of previous-generation vector databases. The company indicates that this decoupled architecture provides a more sustainable foundation for continued innovation in vector search capabilities.
Future enhancements are likely to focus on further improving the latency profile of the storage-optimized tier, potentially through smarter caching strategies, additional compression techniques, or selective loading of index portions. The distributed Spark-based indexing pipeline also opens possibilities for more sophisticated indexing algorithms that can be computed at even larger scales.
As the broader AI industry continues to generate ever-larger embedding datasets, architectures that efficiently separate storage and compute costs are expected to become the standard for production vector infrastructure. Databricks' implementation, deeply integrated with its Lakehouse platform and Mosaic AI capabilities, gives customers building end-to-end AI applications a cohesive solution that spans data processing, embedding generation, indexing, and serving.
The announcement reflects a broader industry trend toward specialized infrastructure for different performance and cost tiers in vector search, similar to the evolution seen in online analytical processing (OLAP) and transactional databases.
Sources
- Decoupled by Design: Billion-Scale Vector Search
- Build billion-scale vector databases in under an hour with GPU acceleration on Amazon OpenSearch Service
- GPU-accelerated vector search in OpenSearch: A new frontier
- High-Throughput, Cost-ffective Billion-Scale Vector Search with a Single GPU
- Scaling Vector Search to 1 Billion on PostgreSQL
- ScyllaDB Brings Massive-Scale Vector Search to Real-Time AI